LeCun、谢赛宁转发的世界模型与VLA共融方案:中关村学院ECCV2026—VLA-JEPA
LeCun、谢赛宁转发的世界模型与VLA共融方案:中关村学院ECCV2026—VLA-JEPA依赖于有限机器人数据和大量人类数据,也能让 VLA 模型更稳健吗?
来自主题: AI技术研报
5745 点击 2026-06-24 10:30
 搜索
搜索
依赖于有限机器人数据和大量人类数据,也能让 VLA 模型更稳健吗?

机器人模型已经能根据“把杯子放进篮子”这类指令完成任务,但用哪只手?

具身智能正以前所未有的速度发展,VLA 模型展现出越来越强的动作和泛化能力。然而,当我们真正把 VLA 模型部署到物理世界时,一个核心挑战浮出水面:实时性。

近日,原力灵机开源的具身智能原生框架 Dexbotic 宣布正式支持以 RLinf 作为其分布式强化学习后端。对具身智能开发者而言,这不仅是一次普通的工程适配,更意味着 VLA 模型研发中长期存在的「SFT 与 RL 割裂」问题,正在被真正打通。
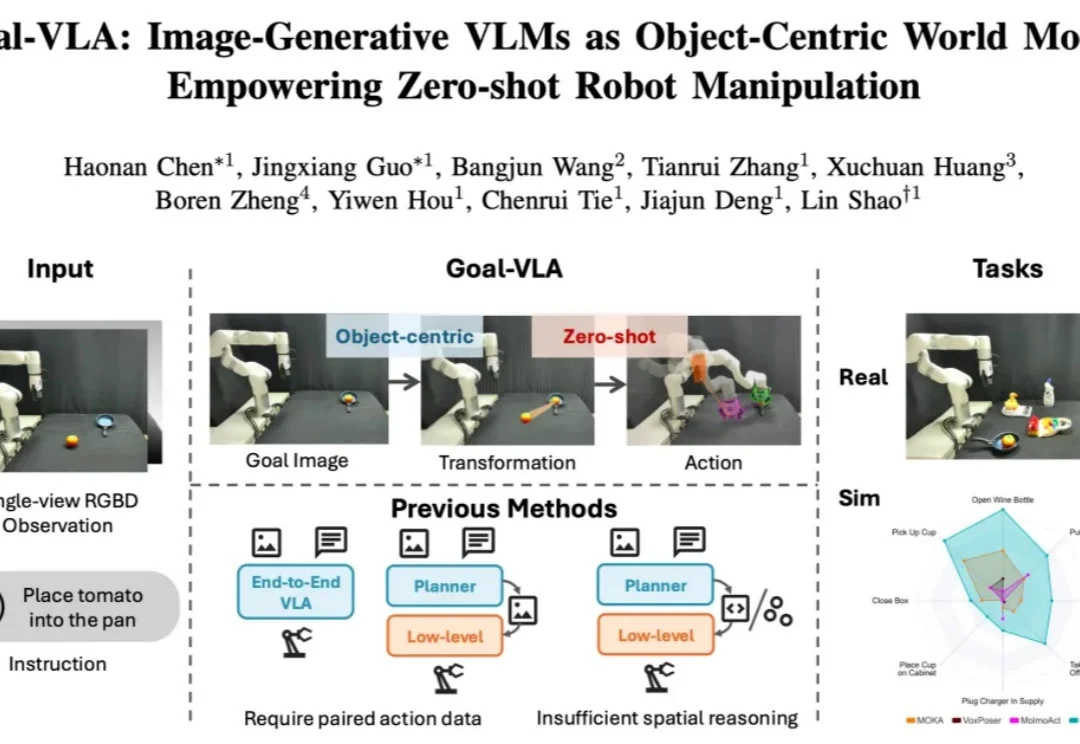
在具身智能领域,机器人操作的泛化能力一直是一个核心挑战。当前,视觉 - 语言 - 动作(VLA)模型主要分为两大范式:端到端模型与分层模型。端到端 VLA 模型(如 RT-2 [1], OpenVLA [2])严重依赖海量的 “指令 - 视觉 - 动作” 成对数据,获取成本极高,导致其在面对新任务或新场景时零样本泛化能力受限。
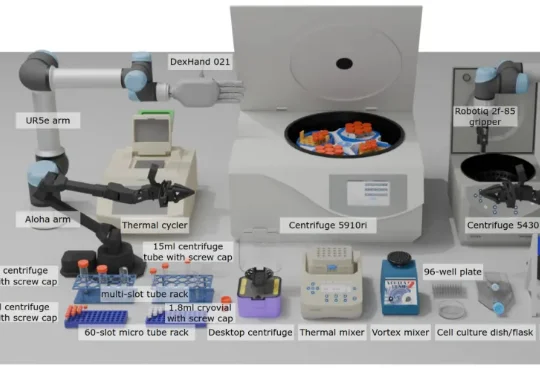
现有 VLA 模型的研究和基准测试多局限于家庭场景(如整理餐桌、折叠衣物),缺乏对专业科学场景(尤其是生物实验室)的适配。生物实验室具有实验流程结构化、操作精度要求高、多模态交互复杂(透明容器、数字界面)等特点,是评估 VLA 模型精准操作、视觉推理和指令遵循能力的理想场景之一。
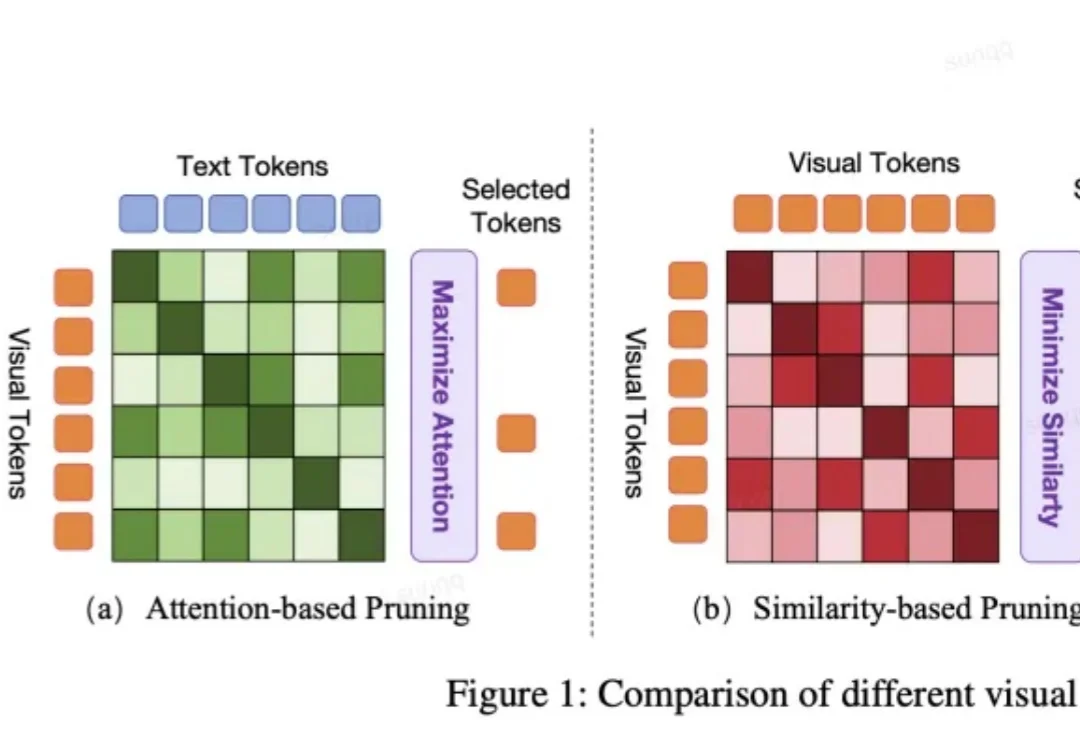
VLA 模型正被越来越多地应用于端到端自动驾驶系统中。然而,VLA 模型中冗长的视觉 token 极大地增加了计算成本。但现有的视觉 token 剪枝方法都不是专为自动驾驶设计的,在自动驾驶场景中都具有局限性。
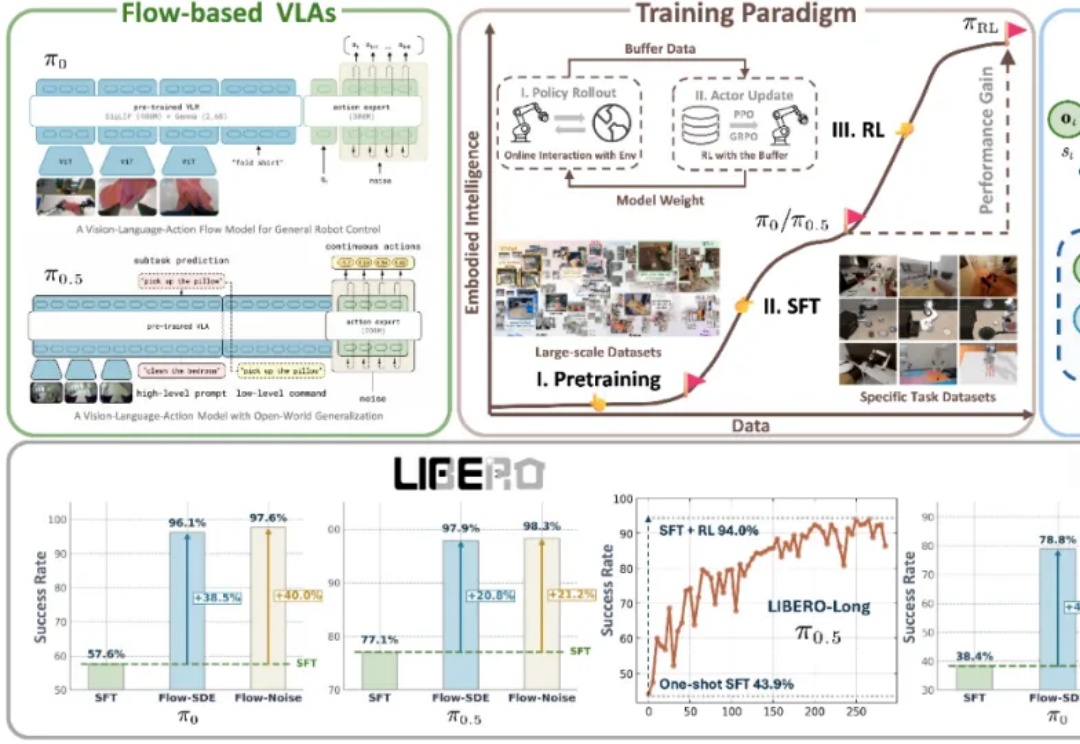
近年来,基于流匹配的 VLA 模型,特别是 Physical Intelligence 发布的 π0 和 π0.5,已经成为机器人领域备受关注的前沿技术路线。流匹配以极简方式建模多峰分布,能够生成高维且平滑的连续动作序列,在应对复杂操控任务时展现出显著优势。

今年,流匹配无疑是机器人学习领域的大热门:作为扩散模型的一种优雅的变体,流匹配凭借简单、好用的特点,成为了机器人底层操作策略的主流手段,并被广泛应用于先进的 VLA 模型之中 —— 无论是 Physical Intelligence 的 ,LeRobot 的 SmolVLA, 英伟达的 GR00T 和近期清华大学发布的 RDT2。
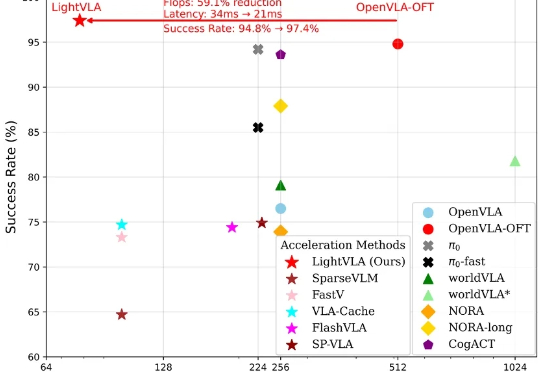
LightVLA 是一个旨在提升 VLA 推理效率且同时提升性能的视觉 token 剪枝框架。当前 VLA 模型在具身智能领域仍面临推理代价大而无法大规模部署的问题,然而大多数免训练剪枝框架依赖于中间注意力输出,并且会面临性能与效率的权衡问题。